채용공고 & 이력서 유사도와 서류전형 결과와의 관계
“왜 누군가는 내가 지원한 채용공고에 서류 합격을 했는데 나는 떨어졌을까?”
“그런 사람들과 나는 어떤 점에서 차이가 있었을까?”
“내가 부족한 점은 무엇일까?”
구직 활동을 해본 사람이라면 한 번쯤(혹은 자주?) 가져봤을 궁금증입니다. 이 프로젝트는 이런 궁금증에서 출발하게 되었는데요, 서류전형 결과에 영향을 미칠 것으로 예상되는 요인 가운데 이력서와 자기소개서가 주는 영향에 대하여 분석을 해보았습니다. 과연 이력서와 자기소개서를 어떻게 작성해야 서류 합격 확률을 높일 수 있을까요?
분석 개요
- 가설
- 채용공고의 내용과 이력서(자기소개서) 내용의 유사도가 서류합격에 유의미한 영향을 미칠 것
- (유사도가 높을수록 서류합격 가능성은 높아질 것)
- 데이터 수집 요건
- 최근 1년간 Wantedlab 플랫폼에 게재된 비즈니스, 개발, 마케팅, 디자인 직군 채용공고에,
- 한국어로 이력서와 자기소개서를 작성하여 지원한 00,000건의 지원 정보
- 분석 프로세스
- 채용공고와 이력서에서 각각 명사 추출
- 채용공고 : 공고명, 주요 업무, 자격요건, 우대사항
- 이력서 : 이력서(출신 학교, 기업, 연차 등의 정보는 제외), 자기소개서
- 각각의 지원 case 마다 채용공고의 단어 묶음과 이력서 단어 묶음의 유사도 측정
- 채용공고별로 합격한 지원건의 유사도 평균과 불합격한 지원건의 유사도 평균 계산
- 합격/불합격 각각의 유사도 평균 차이가 통계적으로 유의미한지 검증
- 채용공고와 이력서에서 각각 명사 추출
분석 관련 이슈 : '유사도'
글이나 문장의 유사도를 측정하는 방법은 다양합니다. 이번 분석에서는 잘 알려진 방법 중 하나인 코사인 유사도(Cosine similarity)와 함께, 코사인 유사도가 갖는 한계를 고려하여, 새로 고안한 측정 방법(가칭: H similarity)을 한 가지 더 추가로 활용했습니다.
1. 코사인 유사도

- 문서 유사도 측정에 많이 활용되는 방법
- 문서에 사용된 단어들에 vector를 부여하고, vector 간의 사잇각을 구해서 얼마나 유사한지 수치로 나타낸 것
- vector 부여 방식은 TFIDF(Term Frequency Inverse Document Frequency) 방식을 적용
- TFIDF : 여러 문서에 자주 등장하는 단어일수록 중요도가 낮고, 유사도 측정에 미치는 영향이 적을 것이라는 idea에서 출발
- 유사도가 높을수록 1에 가깝고, 다를수록 0에 가까움.
2. 또다른 유사도 측정 방법 : H similarity
- 채용공고(A)에 사용된 전체 단어(명사) 중 이력서(B)에 사용된 단어(명사) 수의 비중 (A에 대한 B의 조건부확률 개념과 흡사)
- 자카드 유사도(Jaccard similarity, =(A∩B)/(A∪B))와 비슷하지만, 기준이 되는 문서(채용공고)에 비교 대상 문서(이력서)가 얼마나 ‘부합’하는지 여부를 고려
- 따라서 비교 대상 문서(이력서)의 단어 중 기준 문서(채용공고)와 일치하지 않는 단어는 유사도 산출 시 고려하지 않는 방식
- 유사도가 높을수록 1에 가깝고, 다를수록 0에 가까움.
3. 새로운 유사도 고안 이유
(1) '유사도'의 정의
이번 분석에서 측정하고자 하는 유사도는 ‘기준이 되는 문서(채용공고)’에 ‘비교 대상 문서(이력서)’가 얼마나 ‘부합’하는지 여부와 개념적으로 더 가깝습니다. 하지만, 대부분의 문서 유사도 측정 방식(코사인 유사도 포함)은 비교 대상이 되는 둘 이상의 문서의 여집합(B^c)의 크기가 커질수록 유사도가 낮아지는 문제 발생하게 됩니다. (아래 예시에서 B의 유사도가 더 낮게 측정됨) 만약 ‘이력서의 공고 부합 여부’를 기준으로 유사도를 정의할 경우, 아래에서 A와 B의 유사도가 거의 같게 측정되는 방식이 좀 더 합리적일 것으로 판단했습니다.
(2) 임베딩(embedding)의 필요성
앞서 코사인 유사도 측정 이전에 비교 대상이 되는 모든 문서(채용공고, 이력서)에 등장하는 단어에 vector 값을 부여했습니다. 이것은 모든 문서를 고려하여 단어별로 (TFIDF 개념을 적용하여) 중요도를 산출하고, 이를 유사도 측정에 활용하고자 하기 위함인데요. 하지만, 실제 서류전형 단계에서는 1) 같은 직군/직무의 채용공고라고 할지라도 각각의 공고가 지원자에게 요구/강조하는 내용에는 다소 차이가 있고, 2) 현업담당자/인사담당자는 다량의 지원서를 동시에 검토할 가능성이 낮을 것으로 예상했습니다. (지원서를 한 번에 모아서 비교하며 상대적인 평가 결과를 바탕으로 서류 합/불을 결정하기보다는 지원서를 개별적으로 검토하면서 pass/fail 결정을 내리는 경우가 더 많을 것으로 예상) 그래서 개별 지원건의 유사도를 측정할 때 전체 문서(공고&이력서)의 내용을 모두 고려한 vector 값을 활용해야 할 이유는 크지 않다고 봤습니다.
분석 결과
1. 코사인 유사도 적용 결과
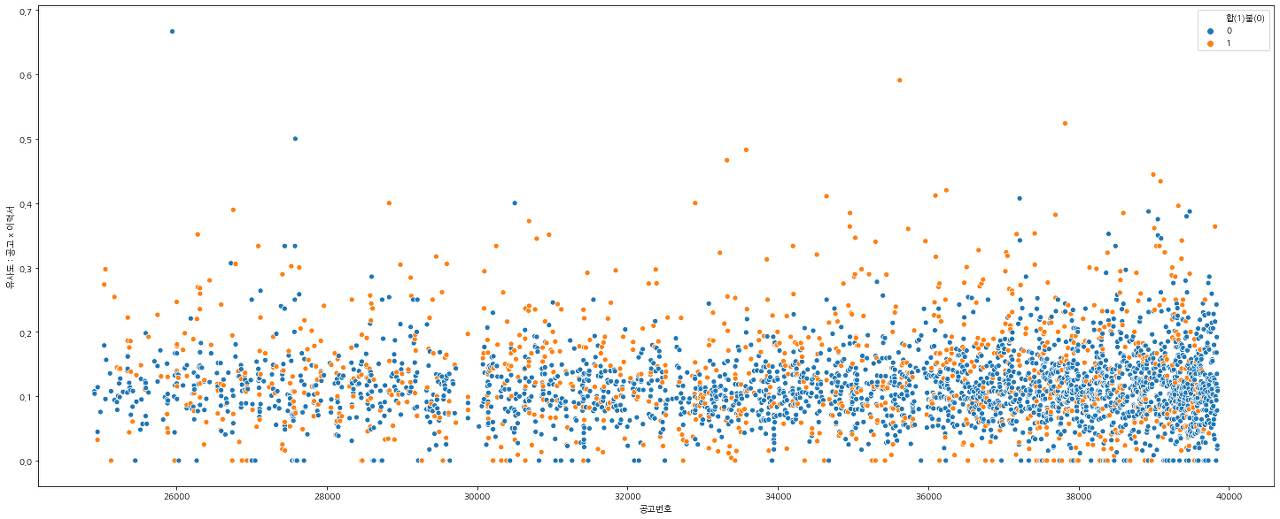
- 합격 / 불합격 유사도 분포
- X축 : 채용공고 리스트, Y축 : 유사도
- 주황색 : 합격, 파란색 : 불합격
- 직군별 합격 / 불합격 유사도 평균 비교
- 좌 : 불합격 , 우 : 합격
- 파랑 : 디자인, 주황 : 개발, 초록 : 비즈, 빨강 : 마케팅
4개 직군 모두 합격 case의 유사도 평균이 불합격 case의 유사도 평균보다 높은 것으로 나타남.
전체 직군 기준, 합격 case의 유사도 평균은 0.106, 불합격은 0.079로, 합격 case가 0.027 더 높게 나타남.
직군별로는 마케팅 직군의 합격/불합격 유사도 GAP 차이가 가장 크게(+0.039) 나타났으며, 디자인이 가장 낮았음(+0.014).
2. H 유사도 적용 결과
- 합격 / 불합격 유사도 분포
- X축 : 채용공고 리스트, Y축 : 유사도
- 주황색 : 합격, 파란색 : 불합격
- 직군별 합격 / 불합격 유사도 평균 비교
- 좌 : 불합격 , 우 : 합격
- 파랑 : 디자인, 주황 : 개발, 초록 : 비즈, 빨강 : 마케팅
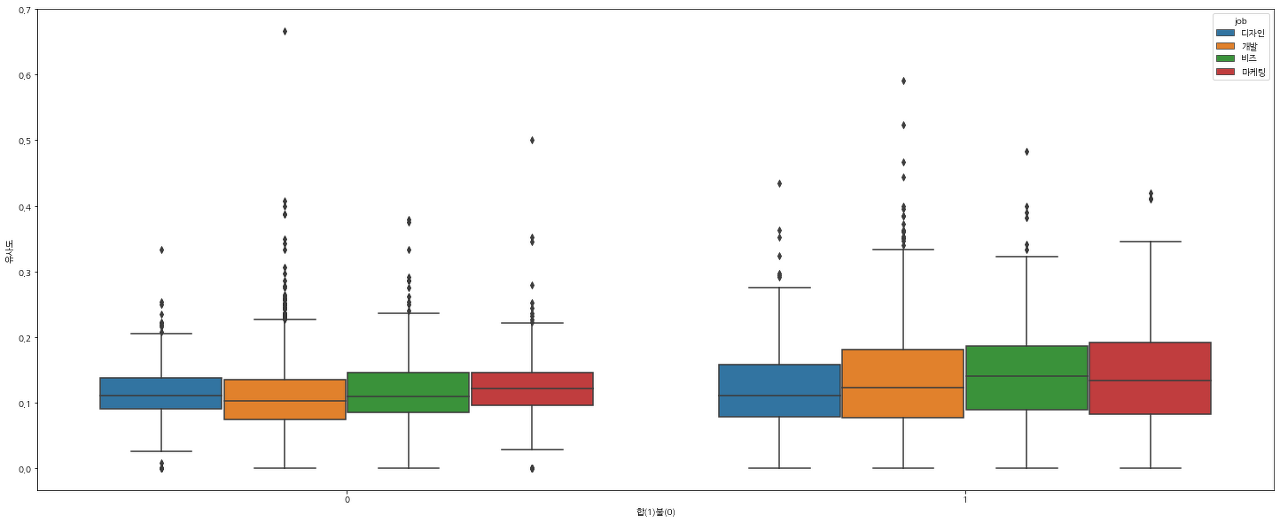
H 유사도를 사용한 경우에도 코사인 유사도를 사용한 경우와 마찬가지로 4개 직군 모두 합격 case의 유사도 평균이 불합격 case의 유사도 평균보다 높은 것으로 나타남.
전체 직군 기준, 합격 case의 유사도 평균은 0.138, 불합격은 0.112로, 합격 case가 0.025 더 높게 나타남.
직군별로는 비즈 직군의 합격/불합격 유사도 GAP 차이가 가장 크게(+0.029) 나타났으며, 디자인이 가장 낮았음(+0.015).
3. 합격 / 불합격 유사도 평균 차이 검증
- 합격 / 불합격 case의 유사도 평균 차이가 통계적으로 유의미한지 검증 진행
- 서로 다른 두 집단(합격 case / 불합격 case)의 유사도 평균을 비교하는 것이므로 두 집단의 분산이 다르다고 가정하고 독립표본(unpaired) T-검정 진행
- p-value < 0.05 이면 통계적으로 유의미 (아래 표)
| 직군 | 코사인 유사도 | H 유사도 |
| Total | 0.000 | 0.000 |
| 디자인 | 0.004 | 0.062 |
| 개발 | 0.000 | 0.000 |
| 비즈 | 0.000 | 0.000 |
| 마케팅 | 0.000 | 0.000 |
코사인 유사도를 사용했을 때, 합격/불합격 평균 차이는 Total & 직군별로 보았을 때 모두 유의미한 것으로 나타남.
H 유사도를 사용했을 때, 디자인 직군을 제외하고는 모두 통계적으로 유의미했음.
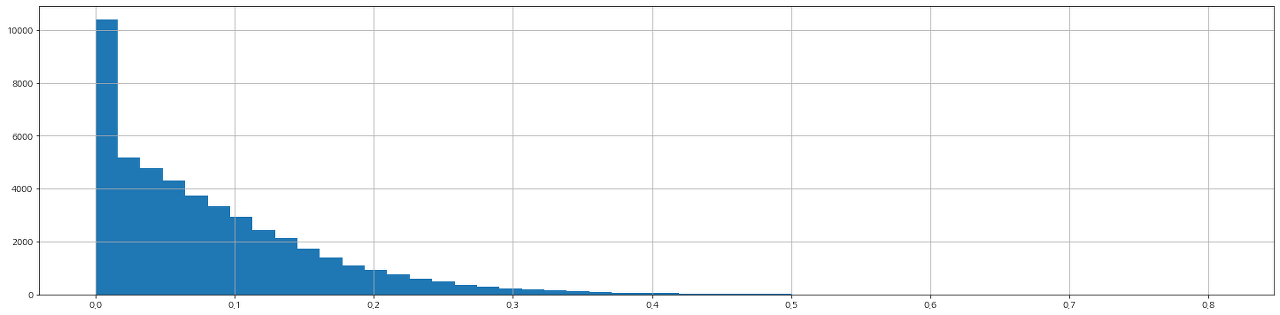
(참고) 코사인 유사도와 H 유사도 비교
- 코사인 유사도 분포
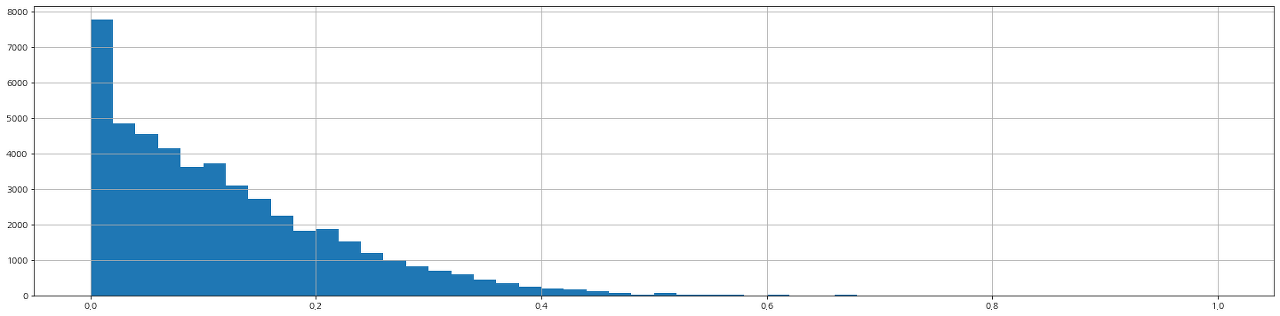
- H 유사도 분포
- 코사인 유사도와 H 유사도의 상관관계
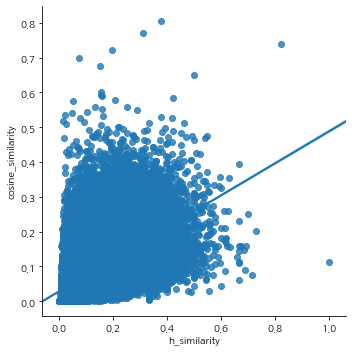
코사인 유사도와 H 유사도의 상관계수는 0.354로 뚜렷한 양적 선형 관계가 있는 것으로 나타남. (참고: 상관계수 해석)
코사인 유사도를 사용한 경우와 H 유사도를 사용한 경우 모두 유사한 분포를 보이고 있고, 유의미한 상관관계가 있는 것으로 나타나고 있습니다. 또한, 분석 결과 역시 비슷하게 나타나고 있어 향후에도 유사한 분석을 진행할 때 H 유사도를 계속해서 활용해볼 가치가 있을 것으로 판단됩니다.
마치며
결과를 종합해 보면 서류 합격 여부에 따라 채용공고와 이력서의 유사도는 의미 있는 차이를 보이고 있으며, 유사도가 높을수록(공고에 포함된 주요 키워드를 많이 포함하여 이력서를 작성할수록) 서류 합격 가능성은 높아질 것으로 기대할 수 있는 것으로 나타났습니다.(일부 직군은 해석에 주의 필요) 어찌 보면 당연한 결과처럼 여겨질 수도 있지만, 분석을 통해 어림짐작으로 미루어볼 수 있었던 부분을 좀 더 명확하게 확인할 수 있었던 사례였다고 정리해 볼 수 있을 것 같습니다.
조금 아쉬운 부분도 있는데요, 분석 결과를 보면 ‘디자인’, ‘개발’ 직군의 경우, ‘비즈니스’, ‘마케팅’ 직군보다 합격/불합격 유사도 차이가 상대적으로 더 작은 모습을 보이는 것으로 나타납니다. 이는 명사 추출 과정에서 ‘한글 명사’만을 추출한 데 기인한 것으로 판단됩니다. 스킬이나, 툴(tool) 활용 능력이 강조되는 ‘디자인’, ‘개발’ 직군을 좀더 제대로 분석하기 위해서는 이것들을 '단어 사전'에 추가하는 작업을 사전에 진행하는 것이 필요할 것으로 보입니다.
앞으로도 재미있는 분석 사례와 결과는 종종 공유를 드릴 수 있도록 하겠습니다. 감사합니다. 😄
이 글은 2년 전 다른 블로그에 게재했던 내용을 다시 정리하여 담은 글입니다.
'데이터 분석 > Analytics' 카테고리의 다른 글
| [행동데이터분석] 인과관계 다이어그램 (1) | 2023.12.21 |
|---|---|
| [행동데이터분석] 행동 데이터를 이해하는 방법 (0) | 2023.12.20 |
| [행동데이터분석] 인과-행동 프레임 워크 (1) | 2023.12.19 |
| Causal Impact - 인과효과 측정을 위한 방법론 (1) | 2022.03.04 |
| [Python] list 형태의 string 값을 list로 변환하기 (0) | 2022.02.08 |




댓글