다차원 데이터, 즉 많은 변수를 사용한 클러스터링 결과를 좀 더 빠르게 확인하기 위해서는 어떻게 해야 할까요?
대부분의 클러스터링 분석 예제를 보면 둘 내지 세 개의 변수를 축으로 산포도(scatter plot) 혹은 3D plot을 그려 클러스터가 어떤 기준으로 묶였는지 확인하는 방법을 제시하고 있습니다. 하지만, 실제 분석 상황에서는 3개 이상의 변수를 활용한 경우가 대부분이고, 클러스터의 수 역시 많아질 수 있기 때문에 산포도를 그려 군집이 어떤 특성을 갖고 있는지 확인하는 방법에는 한계가 존재합니다. 오늘은 기본적인 시각화 방법을 활용하여 클러스터링 결과를 효과적으로 확인하는 방법에 대한 이야기를 해보도록 할게요.
1단계 : 클러스터의 크기 확인
우선 가장 먼저 확인할 부분은 각 클러스터의 크기가 어떠한지, 고르게 나뉘었는지 확인하는 것입니다.
만약 클러스터 종류가 많고, 크기가 유독 작은 클러스터가 눈에 띈다면, 결과 검토 후 다른 클러스터와 합치는(같은 클러스터로 취급) 것 등을 고려해 볼 수 있습니다.
# 시각화에 필요한 모듈 불러오기
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# df : 데이터셋
# cluster : 데이터셋에서 클러스터 결과 컬럼명
cluster_size = df['cluster'].value_count()
(혹은)
cluster_size = df.groupby(['cluster'])['id'].count() # 'id' 대신 아무 컬럼 이름을 적어도 무방
print(cluster_size)
cluster_size.plot(kind = 'bar')
2단계 : 클러스터의 전반적인 특성 차이를 한눈에 보기
클러스터 크기를 확인했으면 그다음은 각 클러스터가 어떤 특징을 갖고 있는지 확인할 차례입니다. 일단 ‘새의 눈’으로 전반적인 특징을 살펴보는 것이 좋을 것 같네요. 가장 널리 사용되고 유용한 기술통계량인 ‘평균’을 사용해보겠습니다. (데이터 특성에 따라 중위수나 최빈값을 사용해 보는 것도 좋습니다.) '클러스터 x 변수' 평균값 히트맵은 아래와 같은 방법으로 그려볼 수 있습니다.
# df : 데이터셋
# cluster : 데이터셋에서 클러스터 결과 컬럼명
# 평균 데이터 테이블 만들기
# 아래에서 데이터 스케일을 조정하는 이유는 히트맵을 그리면 값이 상대적으로 작은 변수의 클러스터간 특징 차이가 보이지 않기 때문입니다. 결국 눈에 잘 띄게 하기 위함!
temp = df.groupby(['cluster']).mean() # 클러스터,변수별 평균 구하기
cluster_mean = temp.transpose() # x축 ↔ y축 전환 (변수들이 y 축으로 배치되게끔)
mean_table = cluster_mean.div(cluster_mean.max(axis=1), axis=0) # 모든 변수의 최대값이 1, 최소값이 0이 되도록 데이터 스케일 조정
# 히트맵으로 그리기
plt.figure(figsize = (20, 25)) # 히트맵 사이즈 설정
annot_kws= {'fontsize':12} # 히트맵 폰트 사이즈 설정
sns.heatmap(mean_table, # 히트맵 그릴 데이터셋
annot=True, # 레이블 표시 여부
fmt='.3f', # 레이블 표시 형식 (소숫점 3째자리까지)
linewidths = 0.1, # 히트맵 선 두께
annot_kws = annot_kws, # 아까 설정한 폰트 사이즈 적용
cmap = 'RdYlBu_r') # 컬러맵 설정
plt.title('클러스터 X 변수 mean table', fontsize=13)
plt.show()결과 테이블이 알록달록 예쁜 것 같아서 이미지를 자르지 않고 통으로 한 번 붙여보았습니다. 😅
이런 형태라면 클러스터(x축) 별로 어떤 변수값을 크게 갖고 있는지 혹은 그렇지 않은지 어느 정도 한눈에 확인이 가능합니다. 또 모든 변수의 최대값과 최소값 스케일을 조정(최대값 1, 최소값 0)했기 때문에 오히려 클러스터뿐만 아니라 변수 간의 상대적인 크기 비교도 좀 더 수월해지는 효과도 있습니다.
3단계 : 변수마다 클러스터 차이 더 자세히 살펴보기
어느 정도 클러스터 윤곽이 그려졌다면 변수별로 클러스터 간의 차이를 좀 더 자세히 살펴볼 차례입니다.
이 부분 역시 박스플롯(box plot)과 바그래프(bar plot)로 간단히 구현해볼 수 있습니다. 어떤 그래프를 사용할지는 변수의 특징에 달려 있습니다. 1 혹은 0으로 코딩된 변수(주로 범주형 변수를 dummy로 만든 변수이거나, 변수가 어떤 행동이나 특징을 가지고 있는지 없는지 여부를 나타내는 경우가 많습니다)는 바그래프(평균)를 사용하면 되고, 일반적인 연속형 변수의 경우, 값의 분포까지 확인하기 위해 박스플롯을 그리는 것을 추천드립니다.
figure, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(nrows=2, ncols=3) # 그래프를 2행 3열로 배치
figure.set_size_inches(30, 10) # 그래프 전체 사이즈 설정
sns.barplot(data = df, y = 'cluster', x = '컬럼1', orient = 'h', ax = ax1) # x축:값, y축:클러스터
sns.barplot(data = df, y = 'cluster', x = '컬럼2', orient = 'h', ax = ax2)
sns.boxplot(data = df, y = 'cluster', x = '컬럼3', orient = 'h', ax = ax3) # boxplot
sns.barplot(data = df, y = 'cluster', x = '컬럼4', orient = 'h', ax = ax4)
sns.barplot(data = df, y = 'cluster', x = '컬럼5', orient = 'h', ax = ax5)
sns.barplot(data = df, y = 'cluster', x = '컬럼6', orient = 'h', ax = ax6)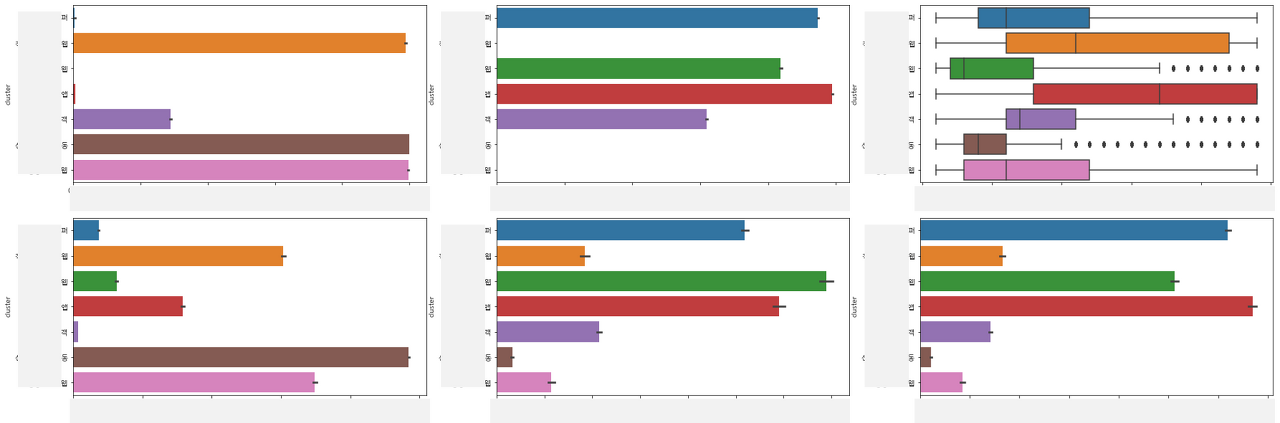
위의 코드를 실행하면 나오는 결과입니다. 성격이 유사한 변수끼리 모아서 위와 같이 바그래프나 박스플롯을 적절히 섞어서 반복적으로 그려보면 좀 더 자세하게 변수별로 클러스터의 특징 비교가 가능합니다.
반복을 통해 최선의 결과 만들기
결과를 그려보는 작업을 여러 차례 반복하면서 변별력이 상대적으로 약한 변수를 제거하거나 새로운 변수를 추가하기도 하고, 클러스터의 수를 다양하게 설정해 보기도 하면서 분석가와 유관부서 담당자들이 납득할만한 클러스터 분류 기준을 찾아가는 과정은 상당한 시간을 필요로 합니다. 이 과정에서 좀 더 빠른 결과 검토를 위해 실제로 분석을 할 때에는 위의 3가지 단계 중 2단계만 시각화하여 공유하고 빠르게 검토하는 과정을 거치기도 했습니다.
어느 정도 작업을 반복하다 보면 클러스터를 구분 짓는 몇 가지 특징들이 눈에 들어오게 되고, 클러스터를 구분짓는 모습이 어떤 범주(?), 기준(?)에서 크게 벗어나지 않는다는 사실을 깨닫게 됩니다. 이때부터는 변수를 조정하는 것보다 클러스터의 수를 적절하게 조절하면서 주요 특징 이외의 다른 몇 가지 특징들로 클러스터가 비교적 명확하게 나뉘는 케이스를 찾는 것이 좋습니다. 또한, 특징이 뚜렷하게 구분되지 않는 클러스터는 다른 클러스터와 합치는 것도 고려해 볼 수 있습니다.
클러스터링 분석에 정답은 없습니다. 완벽한 결과보다는 최선의 결과를 찾아가는 과정으로 이해하는 것이 좋을 것 같습니다. 🙂
'데이터 분석 > Machine Learning' 카테고리의 다른 글
| 클러스터링 분석 - (5) 적정 군집수(k) 찾기 (0) | 2021.12.22 |
|---|---|
| 클러스터링 분석 - (4) 변별력 있는 변수 찾기 (0) | 2021.12.21 |
| 클러스터링 분석 - (3) 스케일 조정 (0) | 2021.12.19 |
| 클러스터링 분석 - (2) 결측값 (0) | 2021.12.19 |
| 클러스터링 분석 - (1) 범주형 변수 (0) | 2021.12.18 |




댓글